

Python实现读取文件夹里Excel文件里的数据
场景描述
已知:文件夹路径、Excel文件名、存放数据的Sheet名
目标:读取目标文件夹里目标Excel里面目标Sheet里的数据
思路
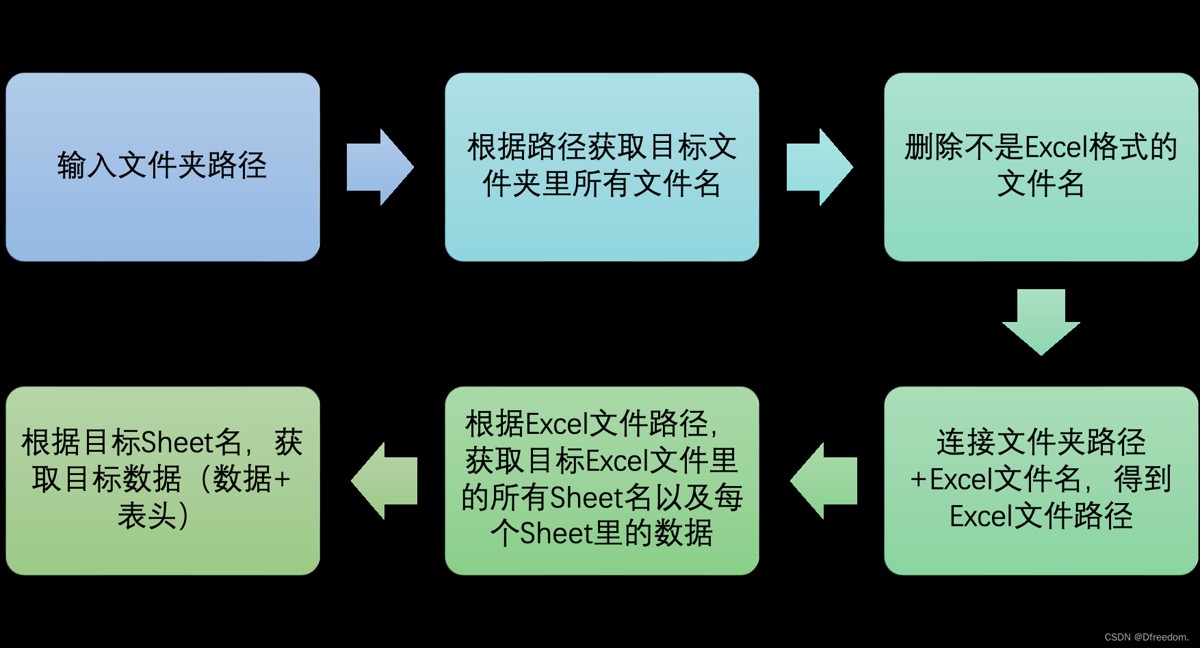
方法一:利用Pandas模块
|
import pandas as pd
import os
#-----获取文件夹中所有的Excel文件名-----#
path ='/Users/Desktop/test.data/' #输入文件夹路径
for root,dirs,files in os.walk(path): #files是文件夹里所有的文件名
for i in range(len(files)):
if '.xlsx' not in files[i]: #删除不是Excel格式的文件名
files[i] = []
else:
files[i] = files[i]
files.remove([])
files.sort() #文件名排序
#-----获取目标Excel里目标sheet里的表头和数据-----#
file_path = path+files[0] #获取目标Excel的路径
raw_data = pd.read_excel(file_path, sheet_name = None,header = None) #获取该路径下,Excel里面所有的数据,数据类型是字典,表格名是键,表格里的数据是值
sheet_names = list(raw_data.keys()) #获取所有表格名
target_sheet_data = raw_data[sheet_names[0]] # #获取目标表格的数据
header_name = target_sheet_data.values[0,:] #获取目标表格名的表头名
target_data = target_sheet_data.values[1:len(target_sheet_data),:] #获取目标表格除表头外的数据
print(header_name)
print(target_data)
|
方法二:利用xlrd模块
|
import xlrd as xd
import numpy as np
import os
#-----获取文件夹中所有的Excel文件名-----#
path ='/Users/Desktop/test.data/' #输入文件夹路径
for root,dirs,files in os.walk(path): #files是文件夹里所有的文件名
for i in range(len(files)):
if '.xlsx' not in files[i]: #删除不是Excel格式的文件名
files[i] = []
else:
files[i] = files[i]
files.remove([])
files.sort() #文件名排序
#-----获取目标Excel里目标sheet里的表头和数据-----#
file_path = path+files[0] #获取目标Excel的路径
data =xd.open_workbook (file_path) #打开路径下的Excel
sheet_names = data.sheet_names() # 获取目标Ecele里所有工作表名称
target_sheet_data = data.sheet_by_name(sheet_names[0]) #获取目标表格的数据
header_name = target_sheet_data .row_values(0) #获取目标表格的表头名
target_data = []
for i in range(target_sheet_data .nrows-1):
target_data.append(target_sheet_data .row_values(i+1)) #获取目标表格除表头以外的数据,列表数据
target_data = np.array(target_data) #转换成数组
print(header_name)
print(target_data)
|
方法补充
1.python批量读取文件夹中的所有excel文件
大数据处理经常要用到一堆表格,然后需要把数据导入一个list中进行各种算法分析,简单讲一下自己的做法:
如何读取excel文件
网上的版本很多,在xlrd模块基础上,找到一些源码:
|
import xdrlib ,sys
import xlrd
def open_excel(file="C:/Users/flyminer/Desktop/新建 Microsoft Excel 工作表.xlsx"):
data = xlrd.open_workbook(file)
return data
#根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_index:表的索引
def excel_table_byindex(file="C:/Users/flyminer/Desktop/新建 Microsoft Excel 工作表.xlsx",colnameindex=0,by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows #行数
ncols = table.ncols #列数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
#根据名称获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_name:Sheet1名称
def excel_table_byname(file="C:/Users/flyminer/Desktop/新建 Microsoft Excel 工作表.xlsx",colnameindex=0,by_name=u'Sheet1'):
data = open_excel(file)
table = data.sheet_by_name(by_name)
nrows = table.nrows #行数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
def main():
tables = excel_table_byindex()
for row in tables:
print(row)
tables = excel_table_byname()
for row in tables:
print(row)
if __name__=="__main__":
main()
|
最后一句是重点,所以这里也给代码人点个赞!
最后一句让代码里的函数都可以被复用,简单地说:假设文件名是a,在程序中import a以后,就可以用a.excel_table_byname()和a.excel_table_byindex()这两个超级好用的函数了。
然后是遍历文件夹取得excel文件以及路径:,原创代码如下:
|
import os
import xlrd
import test_wy
xpath="E:/唐伟捷/电力/电力系统总文件夹/舟山电力"
xtype="xlsx"
typedata = []
name = []
raw_data=[]
file_path=[]
def collect_xls(list_collect,type1):
#取得列表中所有的type文件
for each_element in list_collect:
if isinstance(each_element,list):
collect_xls(each_element,type1)
elif each_element.endswith(type1):
typedata.insert(0,each_element)
return typedata
#读取所有文件夹中的xls文件
def read_xls(path,type2):
#遍历路径文件夹
for file in os.walk(path):
for each_list in file[2]:
file_path=file[0]+"/"+each_list
#os.walk()函数返回三个参数:路径,子文件夹,路径下的文件,利用字符串拼接file[0]和file[2]得到文件的路径
name.insert(0,file_path)
all_xls = collect_xls(name, type2)
#遍历所有type文件路径并读取数据
for evey_name in all_xls:
xls_data = xlrd.open_workbook(evey_name)
for each_sheet in xls_data.sheets():
sheet_data=test_wy.excel_table_byname(evey_name,0,each_sheet.name)
#请参考读取excel文件的代码
raw_data.insert(0, sheet_data)
print(each_sheet.name,":Data has been done.")
return raw_data
a=read_xls(xpath,xtype)
print("Victory")
|
2.Python使用pandas读取目录下所有Excel文件并拼接
首先,我们需要导入pandas库和os库。pandas库用于数据处理,而os库用于操作文件系统。
在Python中,我们可以使用以下代码来读取指定目录下的所有Excel文件:
|
import pandas as pd
import os
# 指定目录路径
dir_path = '/path/to/directory'
# 获取目录下所有Excel文件名
file_names = [f for f in os.listdir(dir_path) if f.endswith('.xlsx') or f.endswith('.xls')]
# 创建一个空的DataFrame用于存储所有数据
df_all = pd.DataFrame()
# 循环读取每个Excel文件,并将它们拼接到df_all中
for file_name in file_names:
file_path = os.path.join(dir_path, file_name)
df = pd.read_excel(file_path)
df_all = df_all.append(df, ignore_index=True)
|
在上面的代码中,我们首先指定了要读取的目录路径。然后,我们使用os库的listdir函数获取该目录下所有以.xlsx或.xls为扩展名的文件名。接下来,我们创建了一个空的DataFrame,用于存储所有数据。然后,我们循环读取每个Excel文件,并使用pandas的read_excel函数将其转换为DataFrame对象。最后,我们将每个DataFrame对象拼接到df_all中。
注意,在拼接DataFrame时,我们使用了ignore_index=True参数。这是因为当我们将多个DataFrame拼接在一起时,默认情况下会保留原来的行索引,这可能会导致重复的行索引。使用ignore_index=True参数可以重新设置行索引,确保每个DataFrame都有唯一的行索引。
另外需要注意的是,如果目录下有多个Excel文件,并且这些文件有相同的列名,那么在拼接时可能会导致列名重复。为了避免这种情况,可以在读取每个Excel文件后将其重命名,以确保每个文件的列名都是唯一的。可以使用以下代码将每个文件的列重命名:
|
df = df.rename(columns=lambda x: f'{file_name}_{x}')
|
在上面的代码中,我们使用了lambda函数来为每个文件的列名添加一个前缀,该前缀是文件名加上下划线。这样就可以确保每个文件的列名都是唯一的。
通过以上步骤,我们就可以使用pandas库在Python中读取指定目录下的所有Excel文件,并将它们拼接成一个大的数据表
来源:https://www.jb51.net/python/355057i93.htm
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com