

Python实现文件查询关键字功能的示例详解
目录
咱们可以想象一个这样的场景,你这边有大量的文件,现在我需要查找一个 序列号:xxxxxx,我想知道这个 序列号:xxxxxx 在哪个文件中。
在没有使用代码脚本的情况下,你可能需要一个文件一个文件打开,然后按 CTRL+F 来进行搜索查询。
那既然我们会使用 python,何不自己写一个呢?本文将实现这样一个工具,且源码全在文章中,只需要复制粘贴即可使用。
思路
主要思路就是通过打开文件夹,获取文件,一个个遍历查找关键字,流程图如下: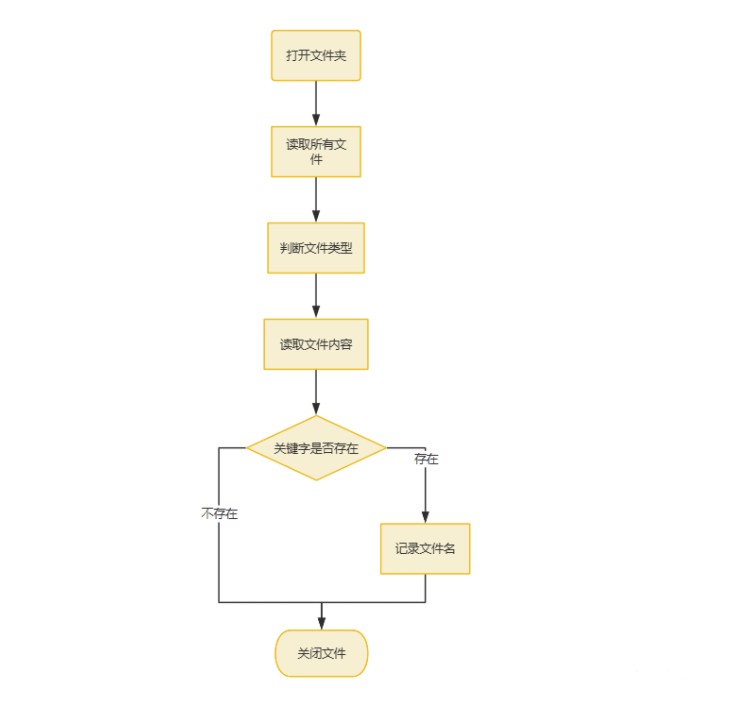

流程图
怎么样,思路非常简单,所以其实实现也不难。
本文将支持少部分文件类型,更多类型需要读者自己实现:
- txt
- docx
- csv
- xlsx
- pptx
读取txt
安装库
|
pipinstallchardet
|
代码
|
importchardet
defdetect_encoding(file_path):
raw_data=None
withopen(file_path,'rb') as f:
forlineinf:
raw_data=line
break
ifraw_dataisNone:
raw_data=f.read()
result=chardet.detect(raw_data)
returnresult['encoding']
defread_txt(file_path, keywords=''):
is_in=False
encoding=detect_encoding(file_path)
withopen(file_path,'r', encoding=encoding) as f:
forlineinf:
ifline.find(keywords) !=-1:
is_in=True
break
returnis_in
|
我们使用了 chardet 库来判断 txt 的编码,以应对不同编码的读取方式。
读取docx
安装库
|
pipinstallpython-docx
|
代码
|
fromdocximportDocument
defread_docx(file_path, keywords=''):
doc=Document(file_path)
is_in=False
forparaindoc.paragraphs:
ifpara.text.find(keywords) !=-1:
is_in=True
break
returnis_in
|
读取csv
代码
|
importcsv
defread_csv(file_path, keywords=''):
is_in=False
encoding=detect_encoding(file_path)
withopen(file_path, mode='r', encoding=encoding) as f:
reader=csv.reader(f)
forrowinreader:
row_text=''.join([str(v)forvinrow])
ifrow_text.find(keywords) !=-1:
is_in=True
break
returnis_in
|
读取xlsx
安装库
|
pipinstallopenpyxl
|
代码
|
fromopenpyxlimportload_workbook
defread_xlsx(file_path, keywords=''):
wb=load_workbook(file_path)
sheet_names=wb.sheetnames
is_in=False
forsheet_nameinsheet_names:
sheet=wb[sheet_name]
forrowinsheet.iter_rows(values_only=True):
row_text=''.join([str(v)forvinrow])
ifrow_text.find(keywords) !=-1:
is_in=True
break
wb.close()
returnis_in
|
读取pptx
安装库
|
pipinstallpython-pptx
|
代码
|
frompptximportPresentation
defread_ppt(ppt_file, keywords=''):
prs=Presentation(ppt_file)
is_in=False
forslideinprs.slides:
forshapeinslide.shapes:
ifshape.has_text_frame:
text_frame=shape.text_frame
forparagraphintext_frame.paragraphs:
forruninparagraph.runs:
ifrun.text.find(keywords) !=-1:
is_in=True
break
returnis_in
|
文件夹递归
为了防止文件夹嵌套导致的问题,我们还有一个文件夹递归的操作。
代码
|
frompathlibimportPath
deflist_files_recursive(directory):
file_paths=[]
forpathinPath(directory).rglob('*'):
ifpath.is_file():
file_paths.append(str(path))
returnfile_paths
|
完整代码
|
# -*- coding: utf-8 -*-
frompptximportPresentation
importchardet
fromdocximportDocument
importcsv
fromopenpyxlimportload_workbook
frompathlibimportPath
defdetect_encoding(file_path):
raw_data=None
withopen(file_path,'rb') as f:
forlineinf:
raw_data=line
break
ifraw_dataisNone:
raw_data=f.read()
result=chardet.detect(raw_data)
returnresult['encoding']
defread_txt(file_path, keywords=''):
is_in=False
encoding=detect_encoding(file_path)
withopen(file_path,'r', encoding=encoding) as f:
forlineinf:
ifline.find(keywords) !=-1:
is_in=True
break
returnis_in
defread_docx(file_path, keywords=''):
doc=Document(file_path)
is_in=False
forparaindoc.paragraphs:
ifpara.text.find(keywords) !=-1:
is_in=True
break
returnis_in
defread_csv(file_path, keywords=''):
is_in=False
encoding=detect_encoding(file_path)
withopen(file_path, mode='r', encoding=encoding) as f:
reader=csv.reader(f)
forrowinreader:
row_text=''.join([str(v)forvinrow])
ifrow_text.find(keywords) !=-1:
is_in=True
break
returnis_in
defread_xlsx(file_path, keywords=''):
wb=load_workbook(file_path)
sheet_names=wb.sheetnames
is_in=False
forsheet_nameinsheet_names:
sheet=wb[sheet_name]
forrowinsheet.iter_rows(values_only=True):
row_text=''.join([str(v)forvinrow])
ifrow_text.find(keywords) !=-1:
is_in=True
break
wb.close()
returnis_in
defread_ppt(ppt_file, keywords=''):
prs=Presentation(ppt_file)
is_in=False
forslideinprs.slides:
forshapeinslide.shapes:
ifshape.has_text_frame:
text_frame=shape.text_frame
forparagraphintext_frame.paragraphs:
forruninparagraph.runs:
ifrun.text.find(keywords) !=-1:
is_in=True
break
returnis_in
deflist_files_recursive(directory):
file_paths=[]
forpathinPath(directory).rglob('*'):
ifpath.is_file():
file_paths.append(str(path))
returnfile_paths
if__name__=='__main__':
keywords='测试关键字'
file_paths=list_files_recursive(r'测试文件夹')
forfile_pathinfile_paths:
iffile_path.endswith('.txt'):
is_in=read_txt(file_path, keywords)
eliffile_path.endswith('.docx'):
is_in=read_docx(file_path, keywords)
eliffile_path.endswith('.csv'):
is_in=read_csv(file_path, keywords)
eliffile_path.endswith('.xlsx'):
is_in=read_xlsx(file_path, keywords)
eliffile_path.endswith('.pptx'):
is_in=read_ppt(file_path, keywords)
ifis_in:
print(file_path)
|
结尾
现在你可以十分方便地使用代码查找出各种文件中是否存在关键字了
以上就是Python实现文件查询关键字功能的示例详解的详细内容,更多关于Python查询文件关键字的资料请关注脚本之家其它相关文章!
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com